Use Mixed Datasets for Training¶
MMPose offers a convenient and versatile solution for training with mixed datasets through its CombinedDataset tool. Acting as a wrapper, it allows for the inclusion of multiple datasets and seamlessly reads and converts data from varying sources into a unified format for model training. The data processing pipeline utilizing CombinedDataset is illustrated in the following figure.
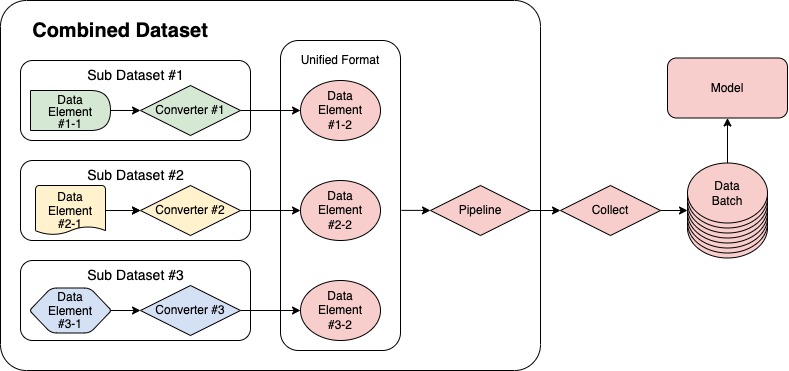
The following section will provide a detailed description of how to configure CombinedDataset with an example that combines the COCO and AI Challenger (AIC) datasets.
COCO & AIC example¶
The COCO and AIC datasets are both human 2D pose datasets, but they differ in the number and order of keypoints. Here are two instances from the respective datasets.

Some keypoints, such as “left hand”, are defined in both datasets, but they have different indices. Specifically, the index for the “left hand” keypoint is 9 in the COCO dataset and 5 in the AIC dataset. Furthermore, each dataset contains unique keypoints that are not present in the counterpart dataset. For instance, the facial keypoints (with indices 0~4) are only defined in the COCO dataset, whereas the “head top” (with index 12) and “neck” (with index 13) keypoints are exclusive to the AIC dataset. The relationship between the keypoints in both datasets is illustrated in the following Venn diagram.

Next, we will discuss two methods of mixing datasets.
Merge
Combine
Merge AIC into COCO¶
If users aim to enhance their model’s performance on the COCO dataset or other similar datasets, they can use the AIC dataset as an auxiliary source. To do so, they should select only the keypoints in AIC dataset that are shared with COCO datasets and ignore the rest. Moreover, the indices of these chosen keypoints in the AIC dataset should be transformed to match the corresponding indices in the COCO dataset.

In this scenario, no data conversion is required for the elements from the COCO dataset. To configure the COCO dataset, use the following code:
dataset_coco = dict(
type='CocoDataset',
data_root='data/coco/',
ann_file='annotations/person_keypoints_train2017.json',
data_prefix=dict(img='train2017/'),
pipeline=[], # Leave the `pipeline` empty, as no conversion is needed
)
For AIC dataset, the order of the keypoints needs to be transformed. MMPose provides a KeypointConverter transform to achieve this. Here’s an example of how to configure the AIC sub dataset:
dataset_aic = dict(
type='AicDataset',
data_root='data/aic/',
ann_file='annotations/aic_train.json',
data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
'keypoint_train_images_20170902/'),
pipeline=[
dict(
type='KeypointConverter',
num_keypoints=17, # same as COCO dataset
mapping=[ # includes index pairs for corresponding keypoints
(0, 6), # index 0 (in AIC) -> index 6 (in COCO)
(1, 8),
(2, 10),
(3, 5),
(4, 7),
(5, 9),
(6, 12),
(7, 14),
(8, 16),
(9, 11),
(10, 13),
(11, 15),
])
],
)
By using the KeypointConverter, the indices of keypoints with indices 0 to 11 will be transformed to corresponding indices among 5 to 16. Meanwhile, the keypoints with indices 12 and 13 will be removed. For the target keypoints with indices 0 to 4, which are not defined in the mapping argument, they will be set as invisible and won’t be used in training.
Once the sub datasets are configured, the CombinedDataset wrapper can be defined as follows:
dataset = dict(
type='CombinedDataset',
# Since the combined dataset has the same data format as COCO,
# it should use the same meta information for the dataset
metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
datasets=[dataset_coco, dataset_aic],
# The pipeline includes typical transforms, such as loading the
# image and data augmentation
pipeline=train_pipeline,
# The sample_ratio_factor controls the sampling ratio of
# each dataset in the combined dataset. The length of sample_ratio_factor
# should match the number of datasets. Each factor indicates the sampling
# ratio of the corresponding dataset relative to its original length.
sample_ratio_factor=[1.0, 0.5]
)
A complete, ready-to-use config file that merges the AIC dataset into the COCO dataset is also available. Users can refer to it for more details and use it as a template to build their own custom dataset.
Combine AIC and COCO¶
The previously mentioned method discards some annotations in the AIC dataset. If users want to use all the information from both datasets, they can combine the two datasets. This means taking the union set of keypoints in both datasets.

In this scenario, both COCO and AIC datasets need to adjust the keypoint indices using KeypointConverter:
dataset_coco = dict(
type='CocoDataset',
data_root='data/coco/',
ann_file='annotations/person_keypoints_train2017.json',
data_prefix=dict(img='train2017/'),
pipeline=[
dict(
type='KeypointConverter',
num_keypoints=19, # the size of union keypoint set
mapping=[
(0, 0),
(1, 1),
# omitted
(16, 16),
])
])
dataset_aic = dict(
type='AicDataset',
data_root='data/aic/',
ann_file='annotations/aic_train.json',
data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
'keypoint_train_images_20170902/'),
pipeline=[
dict(
type='KeypointConverter',
num_keypoints=19, # the size of union keypoint set
mapping=[
(0, 6),
# omitted
(12, 17),
(13, 18),
])
],
)
To account for the fact that the combined dataset has 19 keypoints, which is different from either COCO or AIC dataset, a new dataset meta information file is needed to describe the new dataset. An example of such a file is coco_aic.py, which is based on coco.py but includes several updates:
The paper information of AIC dataset has been added.
The ‘head_top’ and ‘neck’ keypoints, which are unique in AIC, have been added to the
keypoint_info.A skeleton link between ‘head_top’ and ‘neck’ has been added.
The
joint_weightsandsigmashave been extended for the newly added keypoints.
Finally, the combined dataset can be configured as:
dataset = dict(
type='CombinedDataset',
# using new dataset meta information file
metainfo=dict(from_file='configs/_base_/datasets/coco_aic.py'),
datasets=[dataset_coco, dataset_aic],
# The pipeline includes typical transforms, such as loading the
# image and data augmentation
pipeline=train_pipeline,
)
Additionally, the output channel number of the model should be adjusted as the number of keypoints changes. If the users aim to evaluate the model on the COCO dataset, a subset of model outputs must be chosen. This subset can be customized using the output_keypoint_indices argument in test_cfg. Users can refer to the config file, which combines the COCO and AIC dataset, for more details and use it as a template to create their custom dataset.
Sampling Strategy for Mixed Datasets¶
When training with mixed datasets, users often encounter the problem of inconsistent data distributions between different datasets. To address this issue, we provide two different sampling strategies:
Adjust the sampling ratio of each sub dataset
Adjust the ratio of each sub dataset in each batch
Adjust the sampling ratio of each sub dataset¶
In CombinedDataset, we provide the sample_ratio_factor argument to adjust the sampling ratio of each sub dataset.
For example:
If
sample_ratio_factoris[1.0, 0.5], then all data from the first sub dataset will be included in the training, and the second sub dataset will be sampled at a ratio of 0.5.If
sample_ratio_factoris[1.0, 2.0], then all data from the first sub dataset will be included in the training, and the second sub dataset will be sampled at a ratio of 2 times its total number.
Adjust the ratio of each sub dataset in each batch¶
In $MMPOSE/datasets/samplers.py we provide MultiSourceSampler to adjust the ratio of each sub dataset in each batch.
For example:
If
sample_ratio_factoris[1.0, 0.5], then the data volume of the first sub dataset in each batch will be1.0 / (1.0 + 0.5) = 66.7%, and the data volume of the second sub dataset will be0.5 / (1.0 + 0.5) = 33.3%. That is, the first sub dataset will be twice as large as the second sub dataset in each batch.
Users can set the sampler argument in the configuration file:
# data loaders
train_bs = 256
train_dataloader = dict(
batch_size=train_bs,
num_workers=4,
persistent_workers=True,
sampler=dict(
type='MultiSourceSampler',
batch_size=train_bs,
# ratio of sub datasets in each batch
source_ratio=[1.0, 0.5],
shuffle=True,
round_up=True),
dataset=dict(
type='CombinedDataset',
metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
# set sub datasets
datasets=[sub_dataset1, sub_dataset2],
pipeline=train_pipeline,
test_mode=False,
))